

UTF-16的诞生,本身就是史诗级的重大失误。这种编码方案集所有缺点于一身,属于典型的“去其精华,取其糟粕”。既有字节序问题,又有变长的问题,还不兼容 ASCII 。
只有缺点,没有优点。
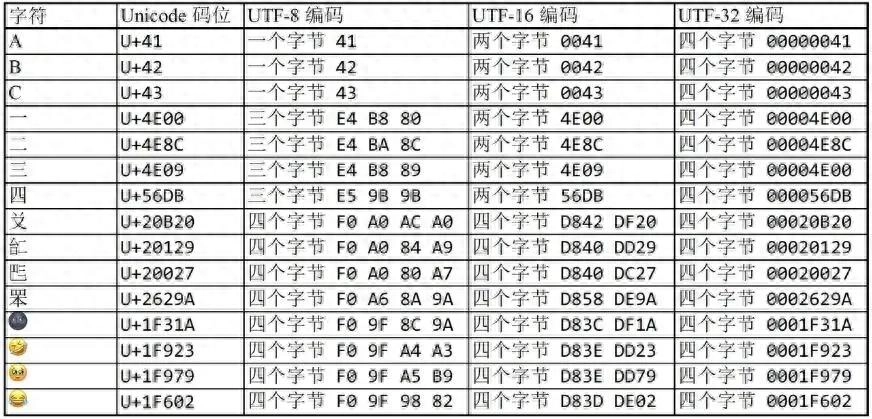
曾经,大家天真地认为两个字节(16位二进制)足以表示一切字符,所以就把Unicode标准与ISO/IEC 10646标准规定了UTF-8和UCS-2(即UTF-16的前身)这两种编码。
UTF-8是兼容ASCII,UCS-2是定长编码。
后来,发现错了:两个字节根本存不下一切字符,需要四个字节(32位二进制)来储存一切字符。于是Unicode与ISO/IEC 10646新标准规定UTF-8、UTF-16、UTF-32三种编码。
UTF-8是兼容ASCII,UTF-32是定长编码,而UTF-16则是为了向下兼容旧标准(UCS-2),重新规定成了一个既不兼容ASCII,又是变长编码,还有字节序问题的垃圾方案。
UTF-16是一个历史性的错误,是应该被扫进历史垃圾堆的东西。
另外,再破除一条谣言:汉字的UTF-16编码是2个字节。
真相:汉字的UTF-16编码是2或4个字节,而且绝大多数(超过70%)是4个字节。
截至2024年,Unicode 15.1已经收录了9万多个汉字。当然其中的8万多个汉字都是我们从未见过的生僻字。这8万多个生僻字当中,有7万多个汉字的UTF-16编码是占4个字节。
















没有回复内容