就在前几天苹果发布了AIMv2


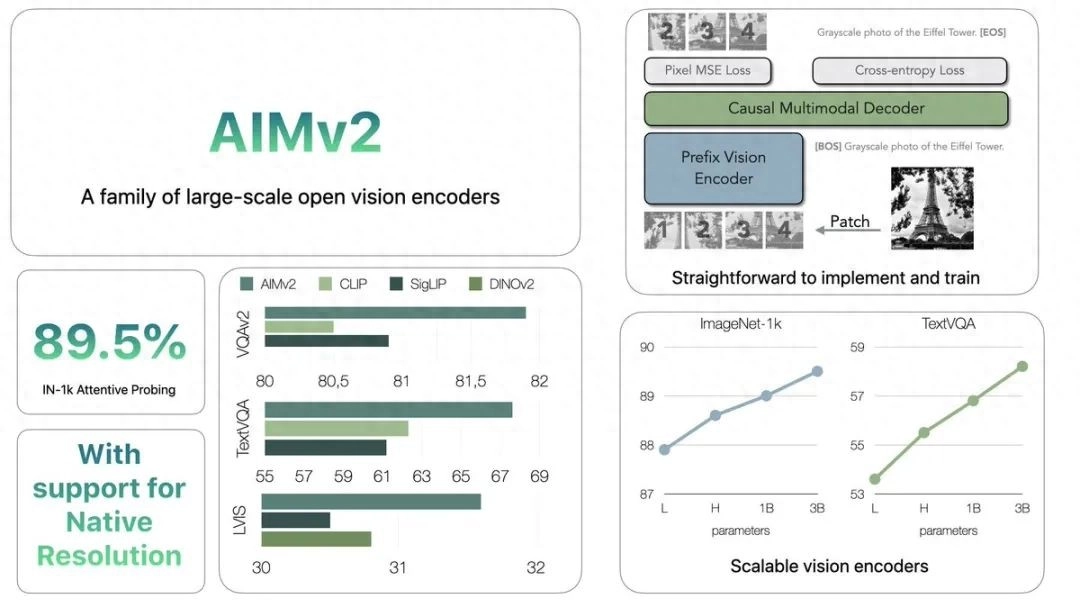
苹果公司悄然发布了名为AIMv2的开源视觉编码器家族!
AIMv2不仅在性能上超越了诸如CLIP、SigLIP等知名模型,还开源了多达19个不同规模的预训练模型,从300M到2.7B参数不等,分辨率更是覆盖了224、336和448三个档位。
解码AIMv2的秘密武器
那么,AIMv2到底有何过人之处呢?
简单来说,它就像是给CLIP装上了一个「解码器」,并采用了自回归训练方式。这种看似简单的改动,却带来了惊人的效果提升。
在ImageNet-1k Attentive Probing任务中,AIMv2以89.5%的成绩傲视群雄。虽然在TextVQA任务上略逊DINOv2一筹,但80.5的得分依然不容小觑。
模块化设计,灵活多变
AIMv2的另一大亮点在于其模块化的设计理念。
从信息图中我们可以看到,它包含了「前缀视觉编码器」、「因果多模态解码器」等关键组件。这种设计不仅提高了模型的可解释性,还为未来的改进和定制化应用铺平了道路。
原生分辨率支持,提升实用性
值得一提的是,AIMv2还支持原生分辨率输入。
这意味着在实际应用中,我们可以直接输入原始图像,无需进行额外的预处理,大大提高了模型的实用性和便利性。
开源共享
更令人兴奋的是,苹果选择了将AIMv2完全开源。

HuggingFace上已经上线了包含19个模型的完整系列,涵盖了从轻量级到重量级的各种规格。这一举措无疑将大大推动视觉AI领域的开放创新。
性能与参数的完美平衡
从苹果提供的性能曲线图中,我们可以清晰地看到AIMv2在不同参数规模下的表现。有趣的是,模型性能并非简单地随参数量增加而线性提升,这为我们在实际应用中选择合适的模型版本提供了重要参考。
不止于视觉
虽然AIMv2主打视觉编码,但其潜力显然不止于此。通过与文本任务的结合,AIMv2展现出了强大的跨模态能力,这为未来在更广泛的多模态应用中发挥作用奠定了基础。
















没有回复内容